
一、前言
作为一个二进制安全从业人员,面对不同的安全分析工具已经是家常便饭,目前业界主流的分析工具是IDA,关于其的博客也有很多,因此这里不再赘述; Ghidra,作为能够与IDA分庭抗礼的一款开源二进制分析工具,相关的资料却不如ida那么丰富,因此这篇推文旨在增加大家对Ghidra的了解。
二、前置介绍
为了避免底层的繁杂,提高逆向工程、自动化分析的效率(最直观的体现就是,避免二进制安全从业人员直接操作不同处理器的不同汇编指令集),几乎每个二进制分析工具都有自己的中间表示(Intermediate Representation,IR),例如IDA的microcode,Binary Ninja的LLIL与MLIL。Ghidra的IR叫做P-Code,一条汇编指令可以直接翻译为一个或多个P-Code(Ghidra文档中称之为Raw-Pcode,顾名思义,原始P-Code,即没有任何附加分析的P-Code),在Raw P-Code的基础上,Ghidra会做一些最基本的数据流分析,并根据分析结果来丰富P-Code集合,Ghidra文档将由数据流等分析引入的P-Code成为Additional P-Code。
P-Code由地址空间、Varnode以及pcode 操作组成,其中地址空间用于抽象程序内部内存,用于表示遗传连续的访问空间,例如register地址空间代表程序的通用寄存器、constant地址空间表示程序的常量;Varnode则抽象单个寄存器或者某一内存地址(可以抽象的里面为某一个变量),例如常量0xdeadbeef或者“bin/bash“可以表示为constant地址空间内的常量varnode;pcode操作类似与机器指令,详细的内容可以参考https://github.com/NationalSecurityAgency/ghidra/blob/master/GhidraDocs/languages/index.html 。
如下是一个例子,在函数代码某一处调用了execl,并传递了对应了参数,编译器会将其编译为对应的汇编代码(连续的LEA、MOV指令加CALL指令),在该汇编指令的基础上,Ghidra通过分析,将其转换为多条P-Code,以下只展示与函数调用直接相关的P-Code(CALL)。
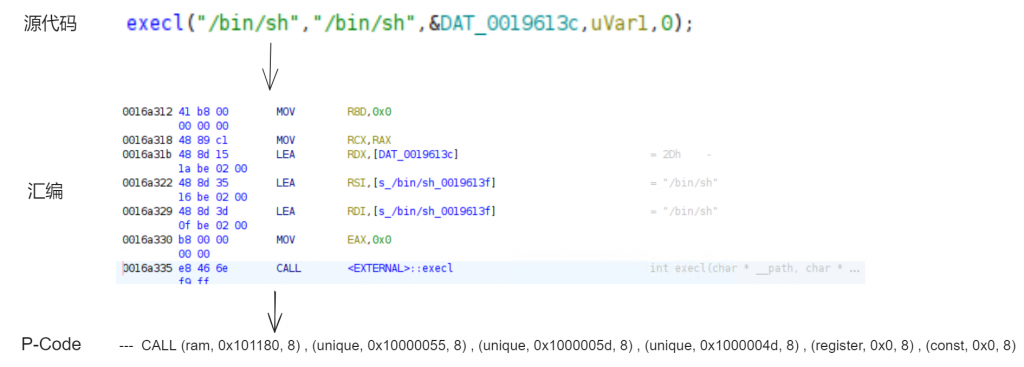
针对Ghidra分析得到的 --- CALL (ram, 0x101180, 8) , (unique, 0x10000055, 8) , (unique, 0x1000005d, 8) , (unique, 0x1000004d, 8) , (register, 0x0, 8) , (const, 0x0, 8) 这样一条CALL指令,CALL即为pcode操作,表示一次函数调用,(unique, 0x10000055, 8) , (unique, 0x1000005d, 8) , (unique, 0x1000004d, 8) 分别表示不同的Varnode,用于抽象一次函数调用不同的实参;(ram, 0x101180, 8)则表示函数execl在程序中的位置,位于ram地址空间的0x101180处长度为8字节的区域中。
Ghidra的P-Code十分丰富(高达67种),以上只是一条简单的例子,详细的介绍参考https://github.com/NationalSecurityAgency/ghidra/blob/master/GhidraDocs/languages/html/pcoderef.html。
三、具体案例

上图为JuiletCWE数据集中存在命令注入漏洞的函数,从源代码层面很容易可以看出可控参数由“ADD“环境变量传入(通过getenv函数),最终在execl中被执行,其对应的数据流为getenv->strncat->execl。其对应的完整P-code指令如下图。这里只展示了与漏洞相关的P-Code指令:

从IR层面则很难去理解,下图标记出每一条CALL指令对应的函数名,可以看到,getenv函数的输出Varnode(register,0x0,8),会直接作为strncat的参数传递,根据strncat的特性,(register,0x0,8)所抽象代表的变量会拼接到(register,0x8,8)代表的变量,从而存在一条数据流由(register,0x0,8)指向(register,0x8,8),即存在一条IR层面的数据流直接从getenv传递到strncat(图中蓝色箭头)。
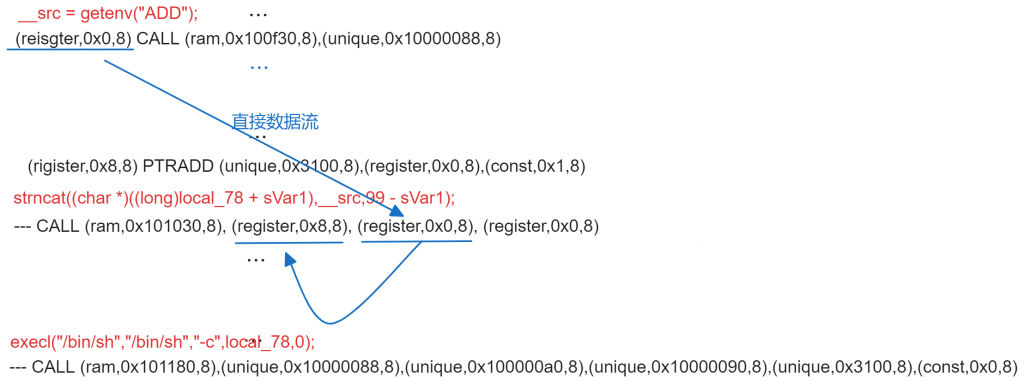
但是通过IR可以发现,数据流传播到(register,0x8,8)之后,我们便很难再找到后继P-Code中与execl对应的CALL P-Code使用过(register,0x8,8),那么getenv的输出是怎么一步步传递到execl?

答案在于PTRADD指令(Ghidra的Additional P-Code),根据Ghidra文档: PTRADD将(unique,0x3100,8)抽象表示的变量当成数组处理(对应于反编译中得local_78),并将其第(register,0x0,8)*(const,0x1,8)处的变量传递给(register,0x8,8),(unique,0x3100,8)+ (register,0x0,8)*(const,0x1,8)结果类似于反编译结果中得local_78+sVar1,并最终将(unique,0x3100,8)作为execl的参数传递(传递的是一个连续的地址,该连续的地址包含可控输入),因此实际存在一条数据流,将(register,0x8,8)与(unique,0X3100,8)关联起来,并最终传递到execl对应的P-Code中。

四、IR层面脚本编写
那么如果从IR层面实现这种类型的漏洞检测呢?如下代码展示了污点传播相关的代码,其中,值得关注的是:为了实现上述污点类型的检测,针对每一次需要传播的Varnode,我们需要追踪其定义(通过varnode.getDef()方法),从而更好的追踪数组或者结构体类型。以上述例子中的(register,0x8,8)为例,其getDef获得的便是对应的PTRADD pcode。
/**
* 数据流传播示例,varnode为待被传播的污点,例如getenv的输出varnode
*
* @param varnode taint that should focus
*/
public void dataflow(Varnode varnode) {
if (varnode == null)
return;
Queue<Varnode> workList = new ArrayDeque<>(Set.of(varnode));
Set<Varnode> processed = Sets.newHashSet();
while (!workList.isEmpty()) {
Varnode vn = workList.poll();
processed.add(vn);
Iterator<PcodeOp> desIter = vn.getDescendants();
while (desIter.hasNext()) {
PcodeOp pcode = desIter.next();
if (pcode.getOpcode() == PcodeOp.CALL) {
/*
如果是函数调用,需要判断是否是sink点,如果是sink点,代表存在一条从污点source传播到sink的路径
*/
Function callee = api.getFunctionAt(pcode.getInput(0).getAddress());
if (sinks.contains(callee.getName())) {
printf("dangerous!taint flow into dangerous function %s\n", callee.getName());
continue;
}
/*
如果是需要额外传播数据流的函数,例如strcat、strncat、memcpy等,则进行数据流传播
*/
if (propogation.containsKey(callee.getName())) {
workList.addAll(propagate(callee.getName(), pcode, vn));
}
} else {
/*
* 如果是ghidra的其他IR,这里只以CAST和COPY为例子,则传播数据流
*/
if (pcode.getOpcode() == PcodeOp.CAST || pcode.getOpcode() == PcodeOp.COPY) {
if (!processed.contains(pcode.getOutput())) {
workList.add(pcode.getOutput());
}
}
}
}
/*
获取varnode定义的地方,加入到worklist中
*/
PcodeOp def = vn.getDef();
if (def != null) {
for (Varnode input : def.getInputs()) {
if (processed.contains(input))
continue;
workList.add(input);
}
}
processed.add(vn);
}
}五、反编译C实现同样的功能
可以看到,作为一个安全从业人员,想要实现一个简单的污点传播,需要详细了解ghidra的IR,上述例子只是冰山一角,实际面对的情况则复杂的多(结构体字段的传播,对象的传播等,即源代码俗称的域敏感);如果需要基于不同的工具开发,例如IDA、binary ninja,则又需要花费大量时间去学习各自对应的IR,所需时间成本太高,那么有什么办法可以减少?
反编译代码其实也值得程序分析人员关注,实际上目前学术界也有着越来越多的研究人员投入的反编译代码的研究中来,例如USENIX24的《A Taxonomy of C Decompiler Fidelity Issues》,ISSTA20的《How Far We Have Come_Testing Decompilation Correctness of C Decompilers》,结果表明反编译结果已经具备一定的成熟度,也可以作为安全人员自动化分析的基石。
处理反编译代码有两种思路,一种是完全脱离反编译器,直接针对反编译结果进行处理,例如将反编译结果作为ANTLR或者Treesitter等词法解析器的输入,定制化处理,这种往往需要杰出的工程能力和丰富的编译知识。另一种是基于反编译器提供的数据结构进行处理,这里我们按照这种思路进行介绍,在Ghidra的底层,反编译的结果都是存在与HighFunction的结构体中,每一个变量有一个抽象的HighSymbol结构体对应,不管是函数的形参、函数局部变量还是全局变量,都存储在HighVariable中;在Ghidra的显示页面,则是由一行行ClangLine构成,每一行ClangLine包含多个ClangToken,其相互之间的逻辑关系可以参考下图:
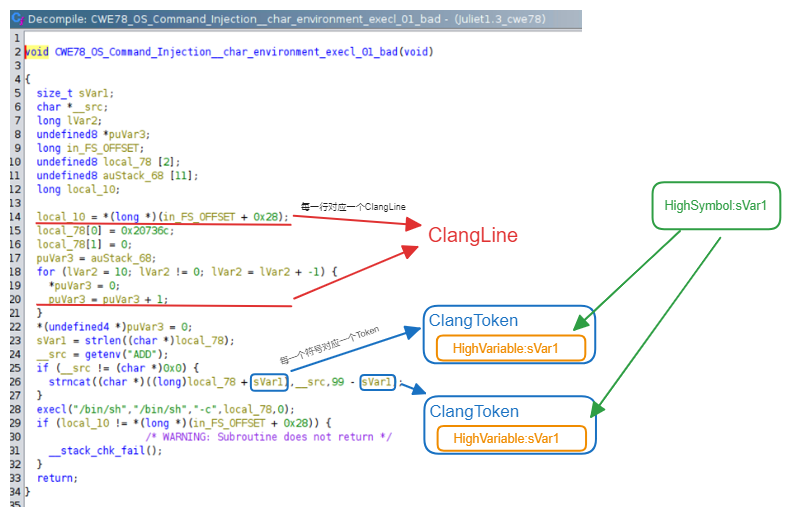
在了解了上述知识之后,我们便可以直接在反编译的结果上进行程序分析,实现从IR层面分析同样的效果。这里只看是追踪数据流的部分代码,对于每一个等待被追踪的变量,可以维护与其相关的变量(这里只是简单的例子,实际处理时需要根据是赋值语句还是load、store等语句类型去进行完备的数据流传播;针对所有可能存在数据流关联的节点,判断其是否属于sink函数。查看完整代码。
/**
* 追踪给定的token范例
*
* @param clines ClangLine 集合
* @param token2trace 等待追踪的污点token
*/
public void dataflow(List<ClangLine> clines, ClangVariableToken token2trace) {
Set<ClangVariableToken> same = Sets.newHashSet();
Set<ClangVariableToken> forward = Sets.newHashSet();
int startLine = clines.indexOf(token2trace.getLineParent());
/*
* 获取与污点相关的所有变量
*/
for (int i = startLine + 1; i < clines.size(); i++) {
ArrayList<ClangToken> tokens = clines.get(i).getAllTokens();
tokens.forEach(t -> {
if (t instanceof ClangVariableToken cvt && t.getText().equals(token2trace.getText())) {
same.add(cvt);
} else if (t instanceof ClangFuncNameToken cft) {
if (propogation.containsKey(cft.getText())) {
{
forward.addAll(propagate(cft, token2trace));
}
}
}
});
}
Set<ClangVariableToken> relatedToken = Sets.newHashSet(same);
relatedToken.addAll(forward);
for (int i = startLine + 1; i < clines.size(); i++) {
ArrayList<ClangToken> tokens = clines.get(i).getAllTokens();
tokens.forEach(t -> {
if (t instanceof ClangFuncNameToken cft) {
if (sinks.contains(cft.getText()) && resolveCallsite(cft).values().stream().anyMatch(v -> relatedToken.contains(v.getText()))) {
{
println("Dangerous");
}
}
}
});
}
}六、总结
这篇文章介绍了ghidra的基本知识(九牛一毛),首先以一个简单的例子引入了对ghidra IR的介绍,并通过一个脚本实现了简单的污点分析,接着从反编译C代码的角度重现了污点传播。IR与反编译代码处理各有优劣,如果不熟悉反编译器的IR,可以尝试从反编译C代码入手写脚本。