
一、前言
大语言模型(LLM)近期成为安全研究和竞赛中的热门话题,涵盖了大模型在安全领域的应用以及自身的安全性等方向,这一趋势为许多非大模型安全研究领域的研究者提供了了解和探索的机会。
得益于强大的上下文理解与模式识别能力,大模型被认为具备从已知漏洞中学习特征并检测、修复未知漏洞的潜力。目前,大多数基于大模型的漏洞检测和修复方案集中在函数级别,只处理小范围的代码片段,不过也有少量研究开始探索代码库级别的问题。
本次 DataCon 聚焦于真实漏洞环境,提供了和漏洞相关的完整程序代码,要求参赛者“结合大模型技术自动化识别出漏洞样例中存在的安全隐患”。为此,本文将从函数级别和代码库级别两个方面简要分析和梳理当前研究进展,并结合代码库级别漏洞检测的需求,探讨未来的研究方向。
二、函数级别漏洞检测
本节主要参考 Large Language Model for Vulnerability Detection and Repair: Literature Review and the Road Ahead,未注明来源的研究方法,可在该综述中查阅。
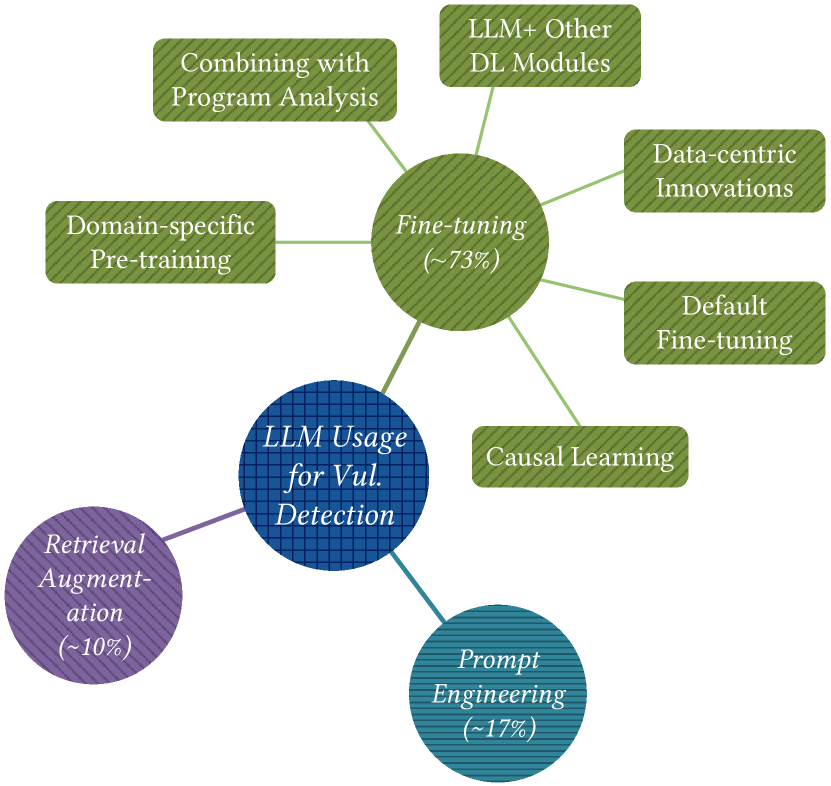
从提升大模型漏洞挖掘能力的角度,主要可以将当前研究分为三种方法:微调、提示工程和检索增强生成(RAG)。微调通过在漏洞数据上的定向训练来调整模型的参数;提示工程则以黑盒的方式,通过精心设计的 prompt 来优化模型在具体应用场景中的输出效果;RAG 从数据库中检索相关知识并整合到 LLM 的上下文中,同样不需要修改 LLM 的参数。
2.1 微调
一般的微调训练包含以下几个步骤:数据准备、模型设计、模型训练和模型优化。根据不同研究方法主要针对的训练阶段,可以划分为以下几个类别:
- 以数据为中心的创新(数据准备)漏洞数据集通常存在标签不平衡和标签不正确的问题。一些研究通过数据采样、伪标签生成以及反事实数据生成等方法,尝试针对这些问题提出解决方案。
- 结合程序分析方法(数据准备)一些研究将程序分析工具的结果引入模型的预训练或微调阶段,以帮助 LLM 更好地理解代码逻辑和数据依赖关系。例如:
- 可以提取抽象语法树(AST)和程序依赖图(PDG)来进行语句级控制依赖和数据依赖的预训练。
- 利用程序切片提取控制和数据依赖信息,将控制流图(CFG)分解为执行路径,为模型提供漏洞检测的支持。
- 结合其他深度学习模型(模型设计)通过 Bi-LSTM (双向长短期记忆网络)处理分段后的代码输入克服了 LLM 的长度限制;亦或是通过 GNN (图神经网络)提取代码的图结构特征来补充 LLM 对代码结构的理解。
- 针对特定领域进行训练(模型训练)通过在特定编程语言和特定漏洞类型的数据上进行预训练,使用如掩码语言模型、对比学习、程序依赖预测和漏洞语句标注等不同的预训练目标,可以增强模型对特定编程语言、特定漏洞模式以及复杂代码依赖关系的理解能力。
- 因果学习(训练优化)通过识别和剔除那些与漏洞标签存在虚假相关的非稳健特征,进而使用因果推理算法来提升模型的因果推理能力。
其中,相比于其他方法更像是在解决一些大模型的通病,“结合程序分析方法”以及“针对特定领域进行训练”两类方法,则更依赖研究者对程序分析和漏洞挖掘领域的深入理解。限于时间原因笔者没能深入了解相关方法的研究细节,感兴趣的读者建议阅读相关论文。
2.2 微调:如何训练自己的模型

那如果我们想要微调自己的大模型,有哪些需要关注的问题呢?首先是选择使用的研究方法:根据数据规模、数据是否标记、模型选择和预算,可以划分为如图所示的模型训练方法。CPT(持续预训练)使用大量未标记的特定领域数据对已经预训练的大模型进行进一步训练;SFT (有监督微调)更专注于增强特定任务的性能,使用有标签的数据进行训练。FULL(全参数微调)细化所有参数,需要大量的计算能力和时间;相比之下,PEFT(参数高效微调)通过仅微调少量模型参数大大降低了计算成本,常见的 LoRA (Low Rank Approximation)就属于 PEFT 方法。在针对于漏洞检测的领域,许多研究采用了 SFT 和 PEFT。
此外,在一个不考虑特殊优化方法的微调过程中,还要涉及模型选择和数据集选择:
- 模型选择

上图统计漏洞挖掘领域中大模型的使用情况,可以看出 CodeBERT 和 ChatGPT 占据了最主要的部分。CodeBERT 是一种针对编程语言的预训练模型,结合了自然语言处理和编程语言理解能力。近期也有研究人员指出,Claude 3 凭借其超大的上下文窗口,整体表现优于 ChatGPT。
- 数据集选择
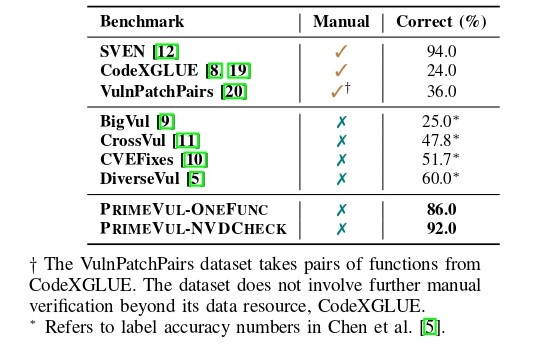
早期研究通常使用 Juliet 和 SARD 等合成数据集来训练模型。后来,一系列基准测试开始从现实世界的开源软件存储库中收集漏洞。然而,现实漏洞数据集存在以下问题:自动标记数据集成本低但粒度过粗,且正确率较低;而手动标记结果虽然可靠,但需要大量的人工成本。
ICSE 2025 上一项工作 PrimeVul 对这些常用的数据集进行了评估,揭示了现有漏洞数据集在正确率上的不足(如图所示),并在 Github 上公开了新的数据集。
2.3 提示工程
另一类优化方法是提示工程,其关键在于设计有效的提示,引导 LLM 在未经专门训练的情况下执行漏洞检测任务。这种方法通常需要依赖大量实验和启发式技巧。根据提示词的交互次数,可以将提示工程分为零次提示和少次提示两种类型:
- 零次提示(Zero-shot Prompting)一方面,广为人知的 prompt 技巧(如任务描述、角色描述、思维链提示等)已被证明能够帮助模型更好地理解和执行特定任务。另一方面,同时提供与程序和漏洞相关的额外信息(例如漏洞类型描述等),也有助于模型更精准地提取程序中的漏洞特征。
- 少次提示(Few-shot Prompting)少次提示的目标是提供一组高质量的示例,每个示例包含目标任务的输入和期望输出,从而进一步提高模型的准确性。例如,在要求模型分析目标函数之前,向其提供相同漏洞类型的漏洞函数作为示例,以帮助模型更好地理解该类型的漏洞。
2.4 检索增强生成
RAG(检索增强生成)是一种用于强化 Few-shot Prompting 的技术,RAG 方法会从训练集中检索与目标测试数据样本相似的标记数据样本,并将这些检索到的样本用作示例,指导大模型对目标数据进行预测。例如,一些工作预先生成包含漏洞代码示例的数据库,在目标函数检测时,通过相似性分析在数据库中检索与目标函数相似的漏洞函数,作为示例一起提供给大模型。
2.5 提示工程:一些示例
本小节让我们一起来看一下 github 上的一些热门辅助工具都使用了哪些 prompt 工程的技巧?
WPeChatGPT (⭐ 1K ) 是一个帮助分析二进制程序的 IDA 插件,可以很方便的让 GPT 分析反编译生成的伪代码。但它内置的提示词只有非常朴素的一句话,实在是还有提升空间。
Find the following C function vulnerabilty and suggest a possible way to exploit it. ChatWithBinary (⭐ 300) 被设计用来解决简单的 CTF 比赛,可以看到这个工具所使用的 prompt 中运用到了一些角色扮演和任务描述的零次提示技巧。
You are PwnGPT: an analyst in the midst of a Capture the Flag (CTF) competition. Your task is to help contestants analyze decompiled C files derived from binary files they provide. You must give the possibility of the vulnerability first Keep in mind that you only have access to the C language files and are not able to ask for any additional information about the files. When you give respones, you must give the location of the vulnerability, and the reason why it is a vulnerability, else, you cannot respone. Utilize your expertise to analyze the C files thoroughly and provide valuable insights to the contestants. Prompt: A contestant in the CTF competition has just submitted a decompiled C file to you for analysis. They are looking for any potential vulnerabilities, weaknesses, or clues that might assist them in the competition. Using only the information provided in the C file, offer a detailed analysis, highlighting any areas of interest or concern. DO NOT GENERATED INFOMATION THAT IS UNSURE And here are some examples:
{
"query": "Is there any insecure use of xxx in this code?",
"answer": "0% NO, the xxx in this code is secure. The code uses the xxx() function from the xxx, which is a secure xxxx. "
}
...vulnhuntr (⭐ 1K)是 ProtectAI 近期开源的一个用于挖掘 python 代码仓库的工具,它针对多种类型的漏洞进行了优化,例如在针对 RCE 漏洞进行挖掘的时候,会额外给出关于漏洞的相关的详细描述,以及给出一些绕过校验的例子来帮助 LLM 判断代码中的输入校验是否可以绕过。
RCE_TEMPLATE = """
Combine the code in <file_code> and <context_code> tags then analyze for remotely-exploitable Remote Code Execution (RCE) vulnerabilities by following the remote user-input call chain of code.
RCE-Specific Focus Areas:
1. High-Risk Functions and Methods:
- eval(), exec(), subprocess modules
- os.system(), os.popen()
- pickle.loads(), yaml.load(), json.loads() with custom decoders
2. Indirect Code Execution:
- Dynamic imports (e.g., __import__())
- Reflection/introspection misuse
- Server-side template injection
3. Command Injection Vectors:
- Shell command composition
- Unsanitized use of user input in system calls
4. Deserialization Vulnerabilities:
- Unsafe deserialization of user-controlled data
5. Example RCE-Specific Bypass Techniques are provided in <example_bypasses></example_bypasses> tags.
When analyzing, consider:
- How user input flows into these high-risk areas
- Potential for filter evasion or sanitization bypasses
- Environment-specific factors (e.g., Python version, OS) affecting exploitability
"""2.6 我们还有多远?
上面提到的各种方法都在自己的实验结果中表现良好,但实际应用情况如何?S&P 2024 上的一项工作,对 228 个代码场景下 8 个先进 LLM 进行评估,涵盖了 C 和 Python 中的 8 种关键的漏洞。结果显示:LLM 的性能因所使用的模型和提示技术而异,说明不同的方法的确能给 LLM 带来不同的程度的性能提升,但研究也发现以下问题:
- 所有分析的模型都有很高的误报率,并且标记了已修补漏洞的代码仍然易受攻击。
- LLM 的输出是不确定的,所有模型都会在一次或多次测试中多次运行并改变答案。
- 即使它们正确识别了漏洞,LLM 为此决定提供的推理解释也往往是不正确的,这让人对其可信度产生质疑。
- LLM 思维链推理不够稳健,即使是简单的代码扩充也可能会使其混淆。
- LLM 无法(难以)检测实际项目中的漏洞。
结论是:即使是最先进的大模型目前也尚未完全准备好用于实际的漏洞检测。尽管目前的结果不尽如人意,但大模型在代码理解方面展现出了非凡潜力,随着近期大模型推理能力的进一步提升,其有望在漏洞检测领域有更显著的进步。
三、代码库级别漏洞检测
相较于函数级别的研究专注于提升大模型直接的漏洞检测能力,代码库级别的研究则更侧重从架构层面进行改进。随着具备更高输入长度容量的 LLM 的出现,存储库级漏洞检测方法作为挖掘现实漏洞不可回避的研究问题,也受到越来越多的关注。
3.1 相关学术研究
截至本文撰写时,我没有找到太多专注于解决代码库级别漏洞检测的研究。不过,在前面提到的研究中,有一些相关的学术工作也值得借鉴和学习。
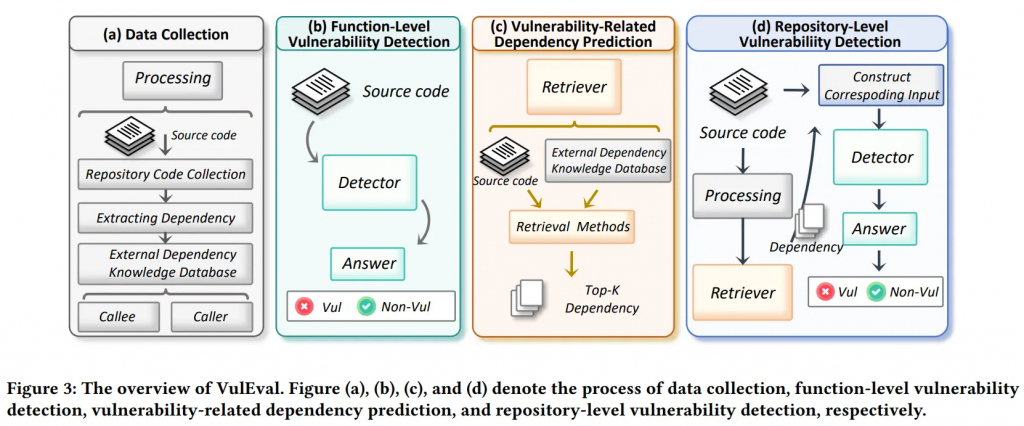
该研究提出了一种名为 VulEval 的评估系统,旨在同时评估软件漏洞检测方法在函数级和代码库级的性能,为此设计了一种简单的代码库级别漏洞检测方法,其本质属于 RAG 方法,主要包含以下步骤:
- 依赖数据库构建:首先使用静态分析工具从补丁文件中提取与漏洞相关的调用者和被调用者信息构建依赖知识数据库。
- 漏洞依赖函数预测:针对输入的代码片段,检索器能够提取其调用的被调用者和调用者信息,基于依赖数据库计算输入代码与每个候选依赖之间的漏洞相关性得分,最终返回最相关的几个依赖函数。
- 代码库级别漏洞检测:最后,检测器使用检索器返回与目标函数相关的依赖函数,然后将这些依赖函数作为上下文与目标函数代码片段一起输入检测器,实现跨函数漏洞的检测。

传统静态分析工具本身更适用于代码库级别的分析,第二个例子实际上是 LLM 辅助静态程序分析。该工作首先分析了传统静态分析工具的缺点:例如 CodeQL 虽然可以有效追踪复杂代码库的污点数据流,但手动编写规范既耗费人力,又容易产生误报,增加开发者负担。
研究提出使用 LLM 来应对这些挑战:首先,利用 LLM 推断特定于项目和漏洞的查询语句;其次,将检测到的代码路径及其周围上下文编码为简单提示,通过 LLM 过滤误报。
此处打个广告:破壳平台(poc.qianxin.com)是由天工实验室推出的二进制漏洞分析工具,使用 VQL(Vulnerability Query Language)作为漏洞查询语言,而 VQL 恰好是很好的接口,可以作为 GPT 和程序的桥梁。
3.2 第一个开源方案:Vulnhuntr
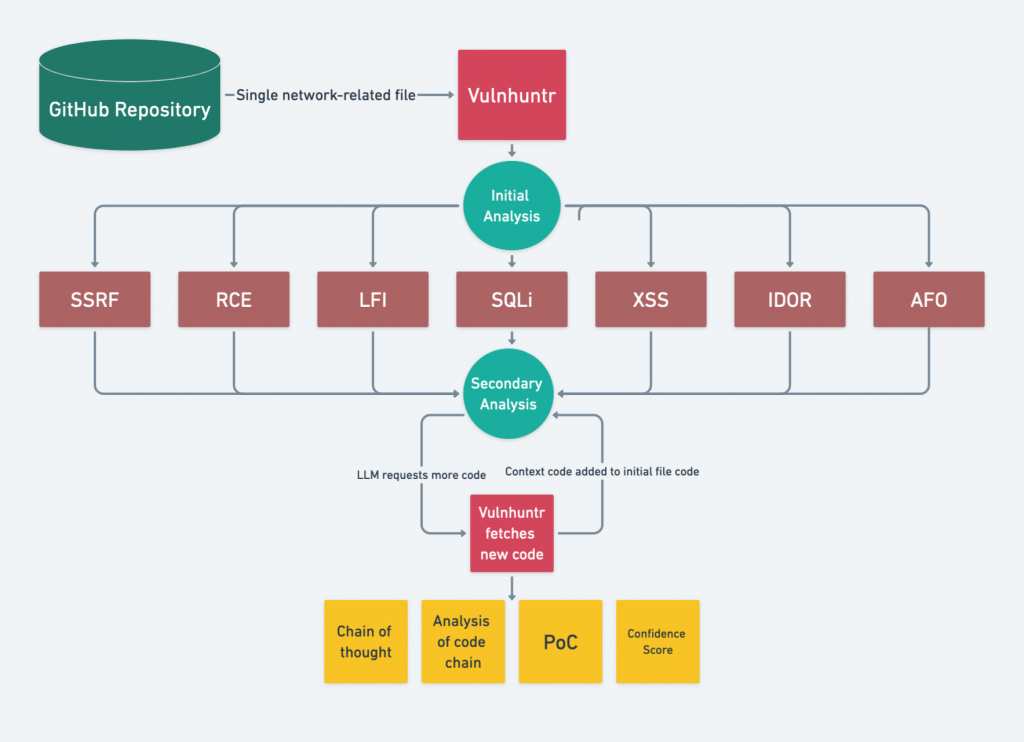
除了学术界的研究,开源社区近期也推出了一个基于 LLM 的漏洞挖掘工具 Vulnhuntr [2],号称发现了全球第一个由自主人工智能发现的 0day 漏洞。
通过给予大模型主动请求代码库函数的能力,Vulnhuntr 能自动创建和分析从用户输入到服务器输出的完整代码调用链,并识别多种漏洞类型的多步骤复杂漏洞。可以通过阅读其源码简要了解工具的运行流程,其分析主要分为以下几个阶段:
- Preparation:工具首先利用项目的 README 来初始化 system prompt,结合了角色扮演、漏洞信息、思维链提示以及格式化输出等 prompt 优化技巧。
- Initial Analysis:对输入的文件进行初步分析,要求大模型识别可能的用户输入 source 点和各种漏洞类型对应的 sink 点,并对所有漏洞类型进行分析。最后,模型会返回潜在的漏洞类型列表。
- Secondary Analysis:根据初始分析中得到的每种潜在漏洞类型,工具要求大模型进一步进行漏洞扫描、代码路径分析和安全控制分析。Prompt 中提供了特定漏洞类型的详细说明,并要求大模型在 source 点到 sink 点的逻辑链条不完整时,主动请求缺失的代码上下文。
- Final Report:大模型被要求给出发现的所有漏洞的详细信息、详细的推理过程和 PoC 以及置信分数。作者表示置信分数超过 7 的结果通常意味着潜在漏洞可能性较大。
作者在 GitHub 上公布了部分由 Vulnhuntr 发现的漏洞列表,看起来躺着挖洞的梦想就快要成为现实(等等,我又失业了)。不过目前该工具只支持检测 python 代码库中的漏洞,考虑到工具的框架与语言类型并无强关联,感兴趣的读者可以尝试将其扩展到其他编程语言。
| Repository | Stars | Vulnerabilities |
|---|---|---|
| gpt_academic | 64k | LFI, XSS |
| ComfyUI | 50k | XSS |
| FastChat | 35k | SSRF |
| REDACTED | 29k | RCE, IDOR |
| REDACTED | 20k | SSRF |
| Ragflow | 16k | RCE |
| REDACTED | 19k | AFO |
| REDACTED | 12k | AFO, IDOR |
四、未来研究方向
4.1 工具集
社区中还有一些尚未公开源码的研究,讨论了一种颇具潜力的端到端框架:通过提供包含静态和动态分析的工具集,让大模型能像人类研究人员一样使用工具来识别和分析漏洞。
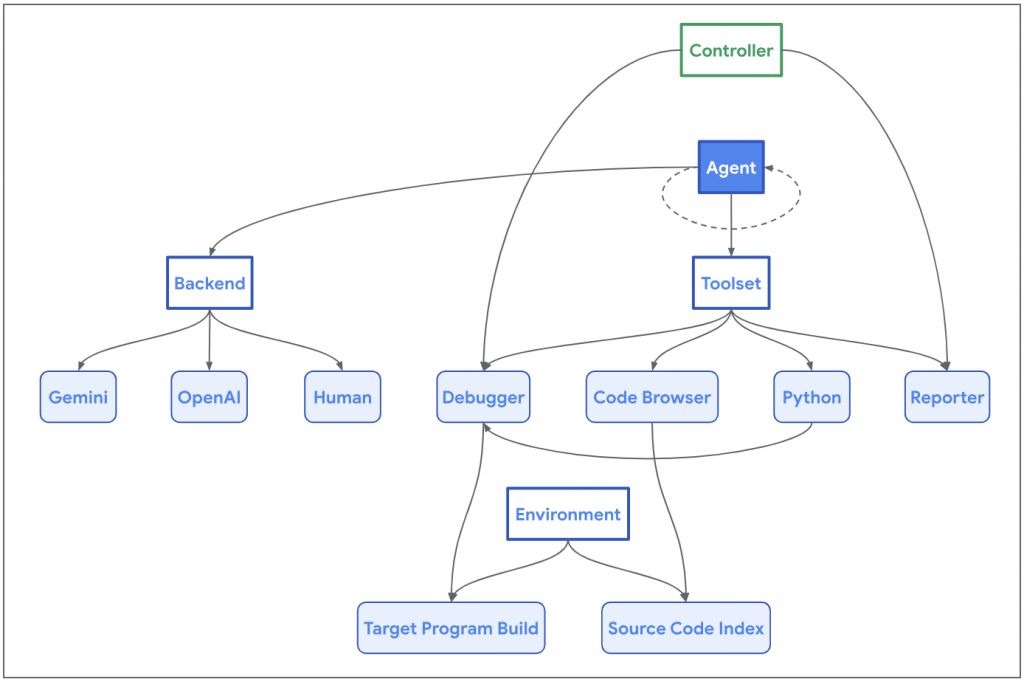
Naptime [4] 由谷歌于今年 6 月提出,通过集成代码浏览器、Python 工具和调试器等组件,使 AI 代理能够模拟人类安全研究人员的工作流程,自动识别和分析代码中的漏洞。
- 代码浏览工具使代理能够浏览目标代码库,为 LLM 提供了查看函数源代码、识别引用函数位置的功能。
- Python 工具使代理能够运行 Python 脚本以进行中间计算,为目标程序生成精确且复杂的输入。
- 调试器工具是最巧妙的部分,它使代理能够与程序交互并观察其在不同输入下的行为。支持设置断点并在这些断点处计算表达式,从而实现动态分析。众所周知动态分析可以很好弥补静态分析假阳性过高的问题。

在去年开始的人工智能网络挑战赛(AIxCC) 中,参赛者被要求开发利用大语言模型自动查找和修复大规模漏洞的工具。挑战项目以现实世界的开源项目为基础:Jenkins、Linux 内核、Nginx、SQLite3 和 Apache Tika。
Team Atlanta [3] 在 8 月于 DEFCON上举行的 AIxCC 半决赛中使用他们的工具发现了 SQLite3 中一个以前未知的空指针解引用,由于比赛尚未完全结束,目前尚无法了解该工具的具体代码实现细节(AIxCC 要求赛后开源工具)。但从他们的博客上可以知道 Team Atlanta 也使用了传统的思维链和微调等技术来增强模型的能力,同时他们在文章中表达了和谷歌研究团队相似的观点:
我们的设计理念很简单:通过 LLM 代理模拟经验丰富的安全研究人员和黑客的思维方式,并通过先进的程序分析技术(动态和静态)进行增强。
有趣的是 Team Atlanta 近期宣布将开始使用他们的工具来尝试完成一些 CTF 挑战。

上周,Project Zero 又发表了一篇重磅文章 [5],称他们受到了 Team Atlanta 在 AIxCC 半决赛比赛中的表现启发,也对 SQLite3 进行了测试,并发现了第一个由大模型代理发现的可利用内存漏洞。
值得一提的是,Big Sleep 的一个关键推动因素是不断在野外发现已知漏洞的变体,研究员认为模糊测试无法很好的捕捉这些变体漏洞,而 LLM 在包含相似语义的漏洞变体分析方面具有显著优势。
文章最精彩的部分在于详细描述了 Big Sleep 如何结合动态调试器等工具,逐步完善漏洞推理的过程。强烈推荐阅读 Project Zero 的原始博客,以下是关键步骤的简要总结:
- 漏洞模式学习:首先,Agent 从某次更新的补丁文件中学习了到了关于“index 错误使用”相关的漏洞信息,并提取出可能涉及漏洞的关键函数。
- 初步变种分析:借助代码浏览工具,Agent 在探索与漏洞相关的代码后,形成了关于该漏洞变体的假设,并尝试运行修改后的测试样例以验证其想法。然而,由于补丁依赖配置中不可用的扩展,调试器遇到了运行时错误,并输出了相关错误信息。
- 进一步分析验证:Agent 从调试器的报错信息中识别出运行失败的具体原因,随后通过分析代码库,学习如何创建一个能够到达目标函数的测试用例。
- 漏洞根因分析:最终,Agent 使用修改后的测试用例成功触发了崩溃。通过与调试器交互来获得崩溃现场的详细信息,Agent 生成了漏洞的根本原因分析及完整的崩溃报告。

这种端到端自动化的漏洞发现过程令人兴奋。然而,考虑到谷歌尚未公布大量由该研究发现的漏洞(这与高度自动化工作能够迅速挖掘漏洞的直觉相悖),可以推测该研究方法在实际应用中仍面临许多现实挑战。
此外在文章中作者也给出了对于 Fuzz 这个漏洞的看法:首先,由于 OSS-Fuzz 中的配置没有开启,所以无法检测到这个漏洞。此外,由于该漏洞不受益与代码覆盖率,并且 AFL 对文本输入的突变不够有效,作者没有能够在短时间内用 AFL 捕捉到这个浅显的漏洞。毕竟模糊测试的一大局限就是不管漏洞多么简单明了,无法到达就无法发现。
4.2 多代理
Multi-agents 方法是一种利用多个代理协作或竞争来提高模型整体性能的技术,这些代理可以是同一个大语言模型的不同实例,也可以是多种专门训练的模型,各自承担不同任务,通过协作、竞争、对话等方式解决复杂问题。
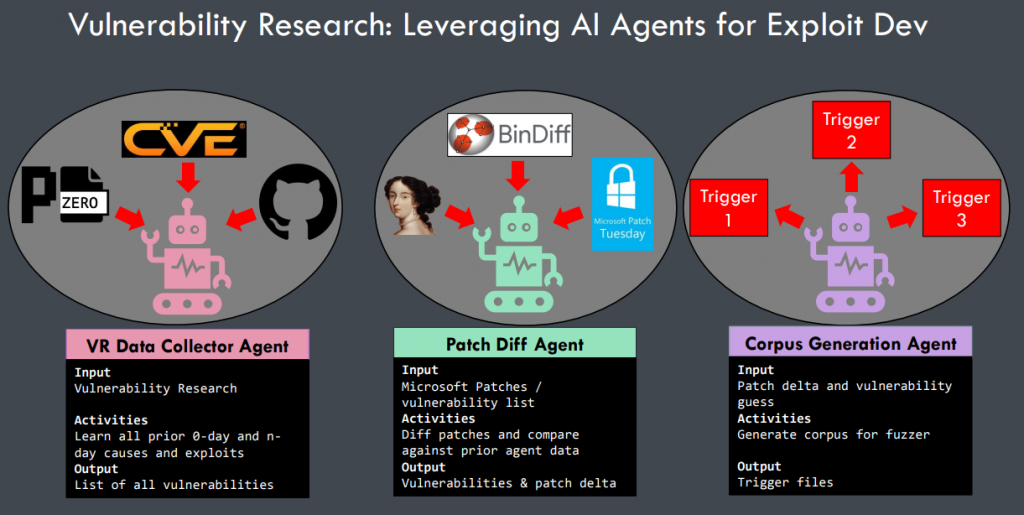
上图是一个关于 “自动从补丁文件中学习得到 PoC” 过程的多代理设计示例,我们也可以照猫画虎来简单设计一个多代理的漏洞挖掘方案:
- Reverse Agent
- 输入:二进制文件
- 活动:逆向程序逻辑,识别 souce 和 sink 点,识别易受攻击的函数和路径
- 输出:易受攻击的函数或路径等
- Pwn Agent
- 输入:易受攻击的函数或路径等
- 活动:基于上下文进行漏洞分析
- 输出:种子(未验证的 PoC)和漏洞摘要
- Fuzz Agent
- 输入:种子(未验证的 PoC)和漏洞摘要
- 活动:生成 harness 并使用种子进行模糊测试
- 输出:PoC 文件
然而,在具体实现一个 multi-agent 框架时会面临更多现实问题。天工实验室的安全研究员在早期研究中对类似架构进行了初步尝试,也遇到了一些挑战,例如出现一个代理输出的内容无法被另一个代理正确解析;代理之间经过多轮交流后容易进入一些“死角”等问题。目前关于这一领域的公开研究较少,尚有许多问题未被系统性地探索和解决。
五、总结
受限于大模型本身的限制,直接利用其对漏洞(特别是代码库级别)进行有效检测仍存在挑战。然而,社区中的一些工作也表明,如何构建一个框架,使得大模型能够像(替代)人类研究员一样使用工具、协作去挖掘真实目标的漏洞,是一个非常有前景的发展方向。
今年 DataCon 的漏洞分析赛道要求选手使用大模型来检测程序中的漏洞,其中许多赛题是由二进制文件反编译生成的代码,伪代码丢失了大量原始语义,为检测过程带来了更大的挑战!期待看到选手们带来创新性的解决方案。
六、参考链接
- Large Language Model for Vulnerability Detection and Repair: Literature Review and the Road Ahead
- https://github.com/protectai/vulnhuntr
- Autonomously Uncovering and Fixing a Hidden Vulnerability in SQLite3 with an LLM-Based System
- Project Naptime: Evaluating Offensive Security Capabilities of Large Language Models
- From Naptime to Big Sleep: Using Large Language Models To Catch Vulnerabilities In Real-World Code